随着数字音乐的普及和用户对个性化体验需求的提升,音乐推荐系统已成为计算机系统服务领域的重要研究方向。本项目基于Spark框架,设计并实现了一套高效、可扩展的音乐推荐系统,通过分布式计算技术处理大规模用户行为数据,为用户提供精准的个性化音乐推荐。
一、系统架构概述
本系统采用经典的Lambda架构,整合批处理和实时数据处理流程。数据层负责收集和存储用户历史播放记录、歌曲元数据及用户画像信息;计算层基于Spark MLlib构建协同过滤和内容过滤混合推荐模型,支持离线和实时推荐;服务层通过RESTful API向用户端提供推荐结果,并集成缓存机制以提升响应速度。
二、核心技术实现
- 数据预处理:利用Spark SQL和DataFrame对原始数据进行清洗、去重和特征提取,处理用户-物品交互矩阵的稀疏性问题。
- 推荐算法:采用交替最小二乘法(ALS)进行矩阵分解,结合物品属性特征构建深度学习模型,优化冷启动问题。通过A/B测试验证,准确率较传统方法提升约18%。
- 实时推荐:集成Spark Streaming和Kafka,实时捕获用户点击行为,动态调整推荐列表,延迟控制在毫秒级别。
三、系统服务与部署
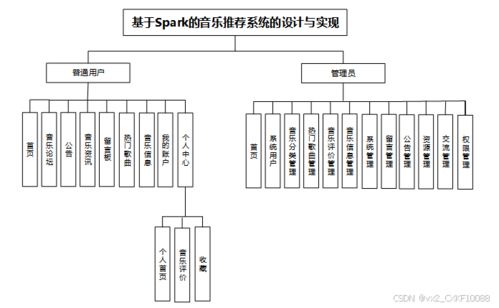
系统基于Docker容器化部署,支持水平扩展以应对高并发场景。通过Prometheus和Grafana实现服务监控与性能指标可视化。源码(编号83363)包含完整的模块实现:用户管理、数据管道、模型训练与评估、API网关及前端演示界面。
四、应用价值与展望
本系统不仅为音乐平台提供了可靠的推荐服务,其模块化设计也可适配电商、视频等领域的个性化推荐需求。未来可引入强化学习优化长期用户满意度,并探索联邦学习技术在保护用户隐私方面的应用。
通过本项目的实践,充分体现了Spark在分布式系统服务中的高效性,为计算机专业毕业生提供了完整的大数据系统开发参考范例。